
The competitive intel that survives a live sales call
How to build battlecards your sales team will actually open — with sourced claims, planted landmines, and zero invented pricing.

Most “competitive intel” in B2B SaaS is a one-pager the founder wrote six months ago, dropped in a shared Notion folder, and hasn’t been updated since. The sales team doesn’t open it during calls. When they do, half the data is stale. The other half is silent on the question that’s actually being asked: “How are you different from [Competitor]?”
So the rep makes something up. Or hedges. Or punts to follow-up email. Either way, the deal slips.
The problem isn’t that your team needs better talkers. It’s that competitive intel built on memory and vibes can’t survive contact with a live sales call. Sales reps need a document they can scan in 30 seconds, with sourced claims they can quote, and counter-positioning scripts that hold up when the buyer pushes back.
When battlecards are systematic, every competitive deal sharpens. The rep knows when to lean in (their three “when we win” scenarios). They know when to walk away (the “red flags” qualification-out criteria). They know which discovery questions expose the competitor’s weaknesses without sounding like a smear. And every claim traces back to a verified source — so the rep isn’t making it up, they’re quoting it.
This is the skill I run when a client’s sales team starts losing competitive deals to one specific competitor — or when a new entrant shows up in the pipeline and nobody knows how to talk about them. It produces a structured 10-section battlecard per competitor, with confidence levels on every claim and explicit [CONFIRM] markers where data is missing.
How it works — visual identity extraction
The skill runs in four phases. Phase 1 confirms the scope (single competitor or batch). Phase 2 pulls intel from upstream skills (competitor-research, win-loss-analysis, product-messaging) and live web research. Phase 3 generates the 10-section battlecard with confidence-tagged claims. Phase 4 validates sources and formats for delivery.
Why screenshots instead of scraping CSS? Because what you *see* is the source of truth. CSS gets compiled, overridden, conditionally loaded. A Framer site injects styles dynamically. A Tailwind build compiles utility classes away. But a screenshot of the live homepage shows you exactly what a visitor sees — the real colors, the actual spacing, the true typography.
Phase 1: Scope confirmation
Before anything else, the skill asks which competitor(s). Single competitor for a deep, deal-specific battlecard. Batch mode (3-5 competitors) when sales needs a competitive landscape view.
It also confirms what intel already exists. Has competitor-research been run on this competitor? Is there a win-loss-analysis output with patterns from real deals? Is there a product-messaging doc with your value props? If yes, the skill inherits those. If no, it triggers them upstream — battlecards are not a substitute for competitor research, they’re the application layer on top of it.
Phase 2: Intel gathering
This is where the skill separates from a one-pager exercise. It pulls from four sources:
→ competitor-research output — the company facts, positioning, feature set, and pricing model already collected → win-loss-analysis output — the actual patterns from won and lost deals (which scenarios you win, which you lose, what objections come up) → product-messaging output — your value props, so counter-positioning isn’t generic but anchored to your actual differentiators → Live web research — the competitor’s current homepage, pricing page, customer logos, recent funding announcements (timestamped to the access date)
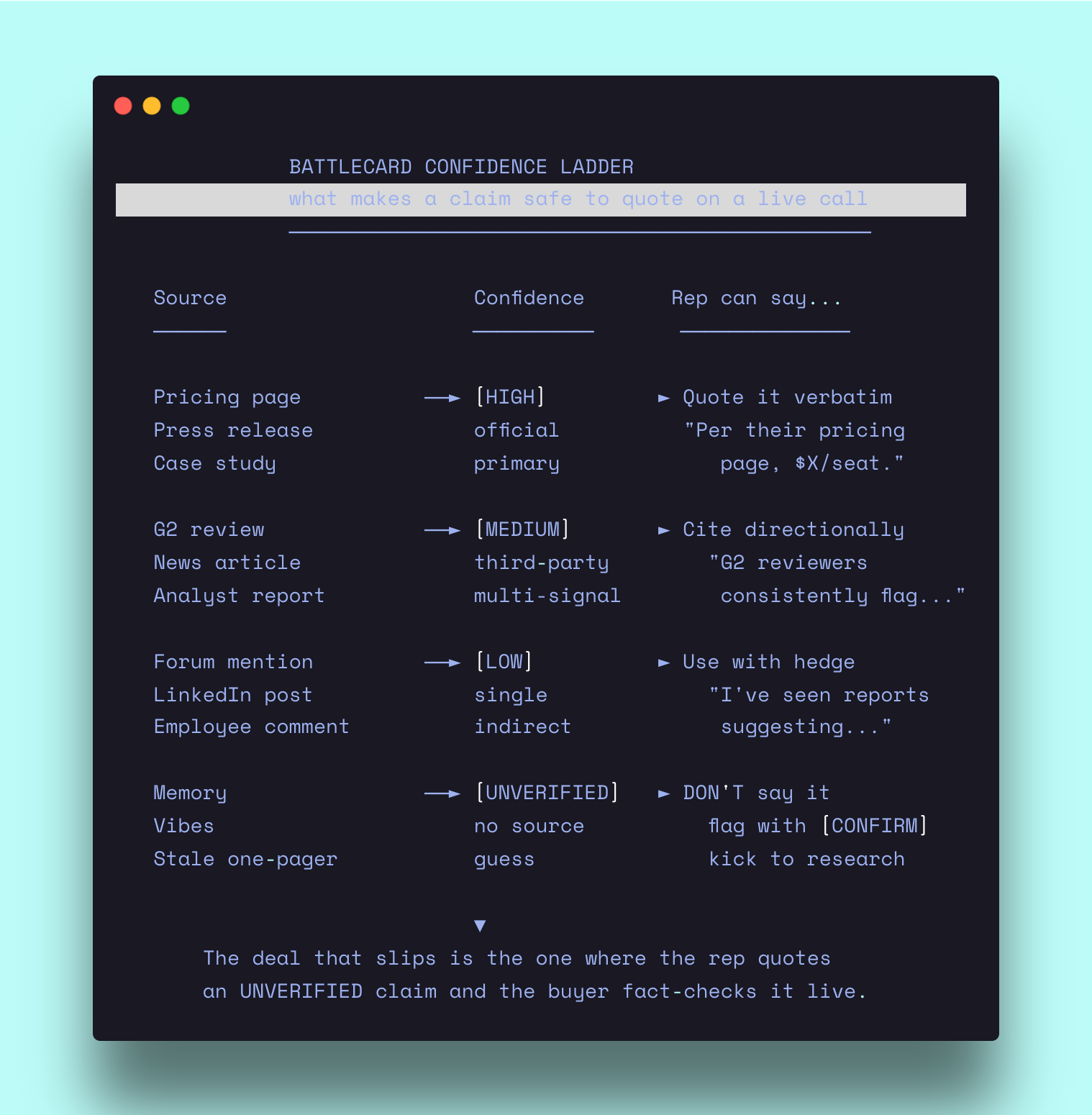
Every fact gets a confidence level: High (direct from official source — pricing page, press release, case study), Medium (third-party with multiple signals — G2, news article), Low (single indirect source — forum mention, employee LinkedIn post), or UNVERIFIED (placeholder for the team to fill in).
Phase 3: The 10-section battlecard
Every battlecard has these sections, in this order, no exceptions:
Quick facts — Founded, funding, employees, target market, pricing model, starting price (side-by-side table with your company)
When we win — 3 specific scenarios + verbatim customer proof point
When we lose — 2+ honest losing scenarios + mitigation actions
Their pitch — Verbatim competitor language pulled from their homepage and sales material
Counter-positioning — Scripted “when they say X, we say Y” responses, tied to your messaging
Feature comparison — Honest side-by-side table with a winner-per-row column
Landmines to plant — 3-5 discovery questions that expose competitor weaknesses
Objection handling — Common objections with proof-pointed responses
Red flags — Qualification-out criteria for when to walk away
Sources — Every claim with URL, access date, and confidence
The “When we lose” section is the one most teams skip. Naming the scenarios where the competitor genuinely beats you builds credibility with sales — it tells reps “here’s the deal you should disqualify, not white-knuckle through.” The mitigation actions are what separate a real battlecard from a marketing brochure.
The “Landmines to plant” section is the part that actually shifts deals. These aren’t claims about the competitor — they’re discovery questions the rep asks the buyer that expose the competitor’s weaknesses through the buyer’s own answers. “How important is real-time collaboration on long-form content for your team?” lands very differently than “We’re better than Competitor X at collaboration.” One is a sales technique. The other is marketing copy in a sales call.
Phase 4: Anti-hallucination layer
Sales credibility dies the first time a rep quotes invented competitor pricing in a deal and the buyer fact-checks it on the call. The skill enforces three guardrails:
→ Never invent competitor pricing. If the pricing page is gated, the skill marks it [UNAVAILABLE — request demo or check Sales Nav] and notes where to find it. Never a guess. → Never fabricate customer quotes. Verbatim only or [PLACEHOLDER: need customer quote — pull from G2 or call recording]. → Confidence levels on everything. A competitor’s stated headcount from their LinkedIn page is High. An estimate from “they look about that size” is UNVERIFIED.
The result is a battlecard a rep can hand to a buyer mid-call without flinching. Every claim has a source. Every gap is named. Nothing is invented.
See it in action
Setup: You’re at Sanity, the structured-content platform built around an all-code backend. You’ve started losing late-stage deals to Hygraph, the GraphQL-native federated content platform. Both companies serve technical buyers in the same headless-CMS bracket. Both publish detailed positioning. The sales team needs a battlecard that explains the difference without sliding into “we’re better.”
Inputs to the skill: → competitor-research output on Hygraph (run the prior week) → Recent win-loss notes from three deals (one won, two lost) with verbatim buyer language → Sanity’s product-messaging library with current value props
What the skill surfaces in the battlecard:
Their pitch (Section 4, verbatim from hygraph.com homepage):
“Federated content platform. GraphQL-native. Build content APIs without compromise.”
Hygraph’s positioning anchor is federation — content from multiple sources unified at the API layer. This is the language the buyer is hearing in the demo. The rep needs to acknowledge it cleanly, not pretend it doesn’t exist.
Counter-positioning (Section 5):
When they say: “We need a federated content layer to unify our existing content sources.” We say: “Federation works when your content already lives in clean structured systems. If you’re starting fresh, the question is what shape your content should take — and that’s a structured-content question, not a federation question. We start with the schema.”
This isn’t a feature comparison. It’s a re-frame. The rep is shifting the buyer’s evaluation criteria from “which platform federates better” to “which platform makes the content modeling decision easier.” That’s the move.
Landmines to plant (Section 7):
→ “What does your current content modeling process look like? How long does a new content type take to ship today?” → “How comfortable is your team writing GraphQL queries directly versus using a typed SDK?” → “When you say ‘federated content,’ which sources are you actually planning to federate — and are those sources already producing structured content?”
The first question surfaces whether the buyer has a real modeling problem. The second question exposes the GraphQL learning curve Hygraph requires. The third question forces the buyer to articulate whether federation solves a real problem they have, or whether it’s a feature they’re attracted to in the abstract.
Red flags (Section 9):
→ Buyer’s primary use case is “we have content scattered across 6+ legacy systems and need an API layer.” Walk away — this is genuinely Hygraph’s territory. → Buyer has zero developer capacity for schema design. Walk away — Sanity’s all-code backend assumes a developer in the loop.
Honest qualification-out criteria. The rep doesn’t fight every deal — they fight the right deals.
Output: A 10-section battlecard with every claim sourced (homepage URL + access date + confidence level), three planted landmines, two honest “when we lose” scenarios, and counter-positioning scripts tied to Sanity’s messaging library. Sales scans it in 30 seconds before the call. The deal doesn’t slip on a question the rep couldn’t answer.
When to use it
→ A specific competitor keeps showing up in late-stage losses. You’ve seen the same name in four lost deals this quarter. The pattern is real. Build a battlecard so the next rep walking into that deal has a structured response, not improvisation.
→ A new competitor enters the market or your pipeline. The buyer mentions a name your team has never heard. Sales is making it up on the call. Build the battlecard before the next deal hits the same buyer-mention stage.
→ Your team launches a feature that overlaps with an incumbent’s positioning. The launch is going to surface comparison questions in every sales call for the next quarter. Battlecards turn that comparison from a stumbling block into a re-framing opportunity.
Get the Skill
Want to run this yourself? The full skill — 10-section template, confidence framework, batch generation, anti-hallucination guardrails, and Google Docs export — is open source:
Save the SKILL.md to your .claude/skills/ folder, then run /battlecards in Claude Code. The skill handles intel pulls from upstream research, structures the battlecard, and tags every claim with a confidence level.
This is one of 100+ GTM skills I’ve built in Claude Code to run positioning, content, and launches for Series A-B SaaS companies.
If you need the whole system, consider working with me.